
Kubernetes: The Unseen Operating System Powering the AI-First World
For DevOps Practitioners: Why Your Next Skillset Must Revolve Around the GenAI Foundation

At The RealOps Reactor, we spend a lot of time looking beyond the hype and into the infrastructure reality of AI.
And after watching Janakiram MSV’s keynote at KubeCon Hyderabad, we couldn’t help but nod in agreement:
The most important element of your GenAI stack isn’t the LLM—it’s the serving engine. And that serving engine is Kubernetes.
Video Source : Keynote: Kubernetes for GenAI: The New Operating System of the AI-First World - Janakiram MSV
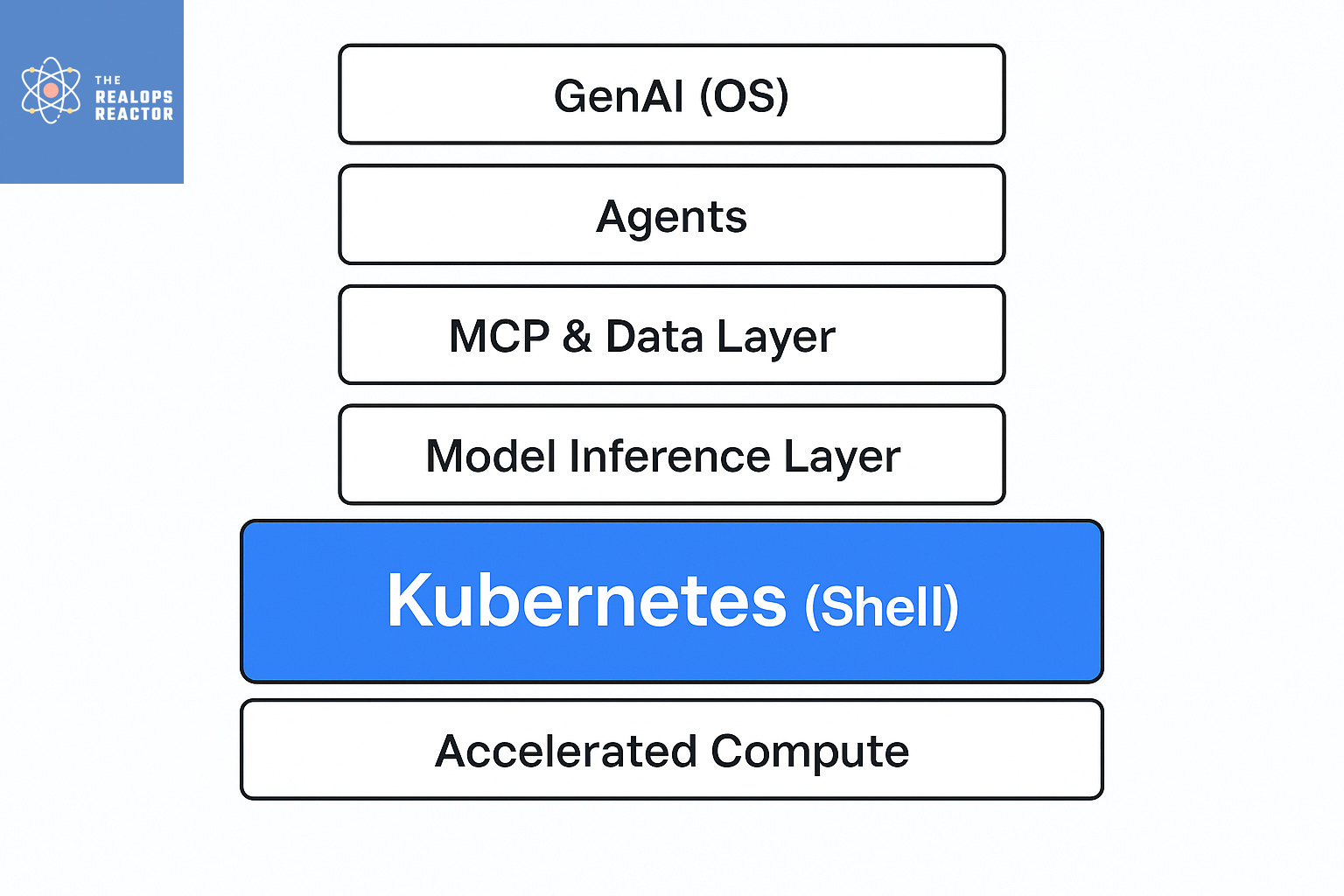
This keynote doesn’t just celebrate Kubernetes—it reframes it. If Generative AI (GenAI) is the new operating system, then LLMs are the kernel, Kubernetes is the shell, and agents are the new applications.
This is more than a catchy metaphor—it’s a roadmap for where our industry is headed.
Why Kubernetes Is the GenAI Shell
Janakiram illustrated the scale of today’s AI workloads with numbers that should make every DevOps and MLOps engineer pay attention:
OpenAI (2021): 7,500 nodes for AI inference
Google (2024): 65,000 AI-optimized nodes
Amazon EKS (2024): 100,000-node clusters for AI workloads
This level of scaling doesn’t happen without a battle-tested orchestrator. Kubernetes has evolved from “microservices scheduler” to “AI workload backbone.”
In our view, the most exciting part of this evolution is how well Kubernetes is adapting to AI’s unique needs:
Specialized hardware abstraction: GPUs, TPUs, FPGAs—no longer exotic; they’re first-class citizens in the Kubernetes ecosystem.
Dynamic Resource Allocation (DRA): In versions 1.33 and 1.34, DRA finally makes GPU consumption sane for platform teams.
Workload diversity: From inference to fine-tuning, training, and distributed serving—Kubernetes runs it all.
The GPU Utilization Reality Check
One point Janakiram made that resonated deeply with us: GPU utilization is still embarrassingly low in many orgs.
We’ve seen this firsthand—teams invest in expensive accelerators, then let them idle because scheduling and sharing are hard.
Kubernetes fixes this by combining:
Device plugins & operators for seamless accelerator integration
Advanced schedulers like Nvidia’s open-sourced Kai scheduler (Run:AI)
Shared GPU tech like Nvidia MIG & vGPU for slicing resources efficiently
If you’re serious about running AI in production, mastering GPU-aware Kubernetes operations is no longer optional.
The Full GenAI Stack on Kubernetes
Janakiram’s keynote breaks the GenAI stack into layers—we think of it as a pyramid:
Agents (The Apps) – Tomorrow’s software is intelligent agents. Already, tools like K Agent (Solo.io) and Google ADK run natively on Kubernetes.
MCP & Data Layer – The Managed Control Plane connects models to the outside world. Kubernetes’ support for both stateful and stateless workloads makes it ideal for MCPs, vector databases, and RAG (Retrieval-Augmented Generation) engines.
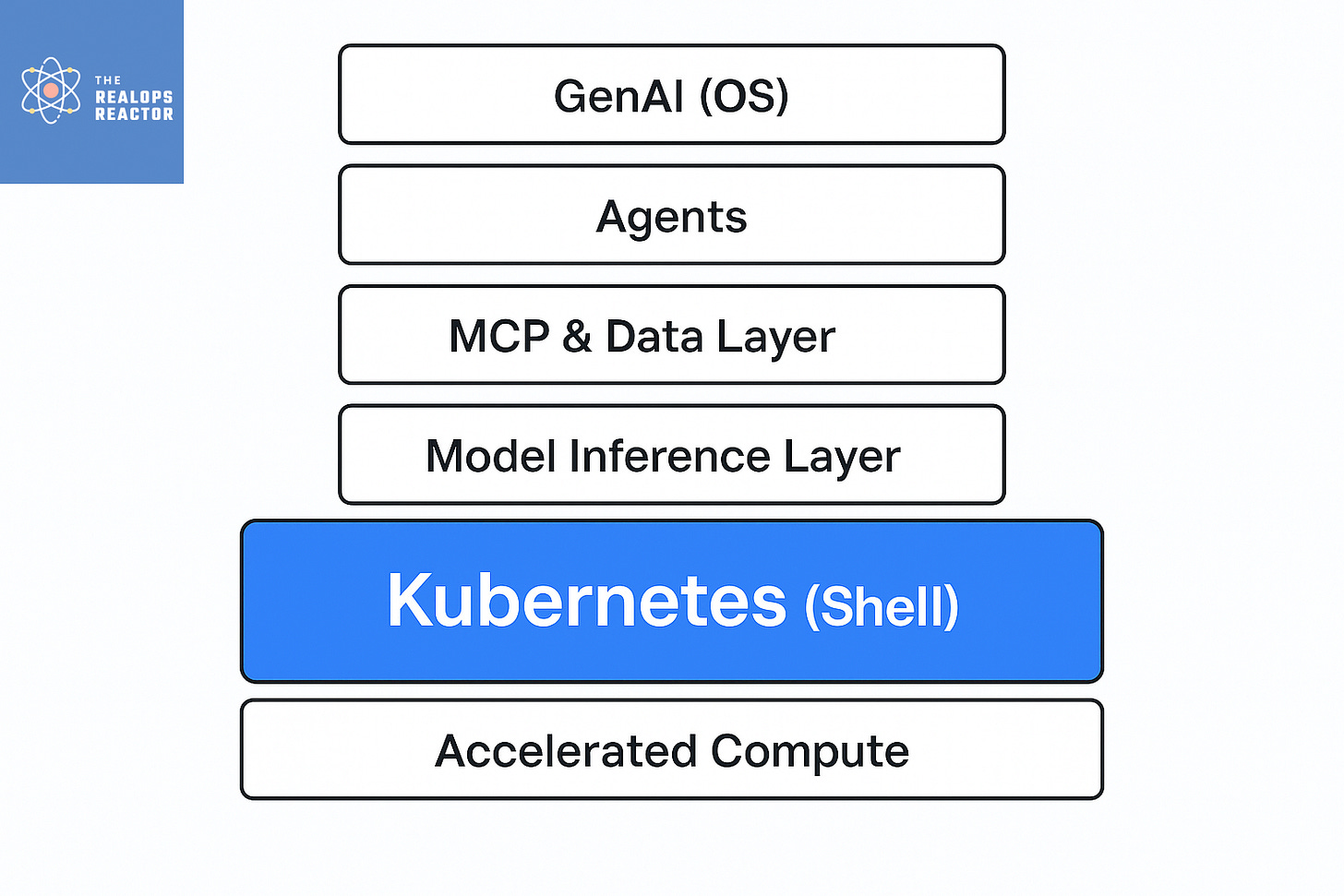
Model Inference Layer – Projects like Kubeflow, KServe, and Q are essential. New serving engines like LLMD (Google + Red Hat) and Nvidia Dynamo are built cloud-native from day one.
Accelerated Compute – GPUs, TPUs, FPGAs—provisioned, scheduled, and scaled by Kubernetes.
The Commercial Ecosystem Is Already There
It’s not just open source. The enterprise AI stack is already leaning on Kubernetes:
Ray (Anyscale) for distributed training & job scheduling
Amazon EKS with 100k-node AI-ready clusters
Azure’s Kao Operator for running LLMs in a cloud-native way
Specialized providers like Coreweave & Lambda Labs—even if they hide Kubernetes, they’re running it under the hood.
Our Recommendations: What to Start Learning Now
At The RealOps Reactor, we believe DevOps and MLOps professionals need to retool fast to stay relevant in the AI-first world. Based on this keynote and our experience, here’s what we’d focus on right now:
GPU-Aware Kubernetes Ops – Learn to schedule, share, and monitor accelerators.
AI Model Serving Frameworks – Hands-on with Kubeflow, KServe, Q, LLMD.
MCP & RAG Architectures – Build MCP workloads, deploy vector databases, connect them to inference pipelines.
Multi-Agent Orchestration – Experiment with K Agent, Google ADK, and emerging agent frameworks on Kubernetes.
Observability for AI Workloads – Extend your Grafana/Prometheus skills to GPU metrics, model performance, and agent orchestration.
Cloud-Native AI Scaling – Understand how EKS, GKE, and AKS implement AI scaling primitives.
The Bottom Line
Kubernetes is no longer “just” the DevOps platform—it’s becoming the universal orchestrator for AI.
If GenAI is the OS, LLMs are the kernel, and agents are the apps, then Kubernetes is the shell binding it all together.
At The RealOps Reactor, our stance is clear:
If you want to build, deploy, and operate in the AI-first world, you need to master Kubernetes for AI workloads—not as a nice-to-have, but as a career necessity.
This is sharp, makes me wonder. Do you see DevOps folks shifting fast to GenAI skills or dragging their feet?